

robgibbon
on 23 May 2024
Can it play Doom? Running an AI LAN party on a Spark cluster with ViZDoom
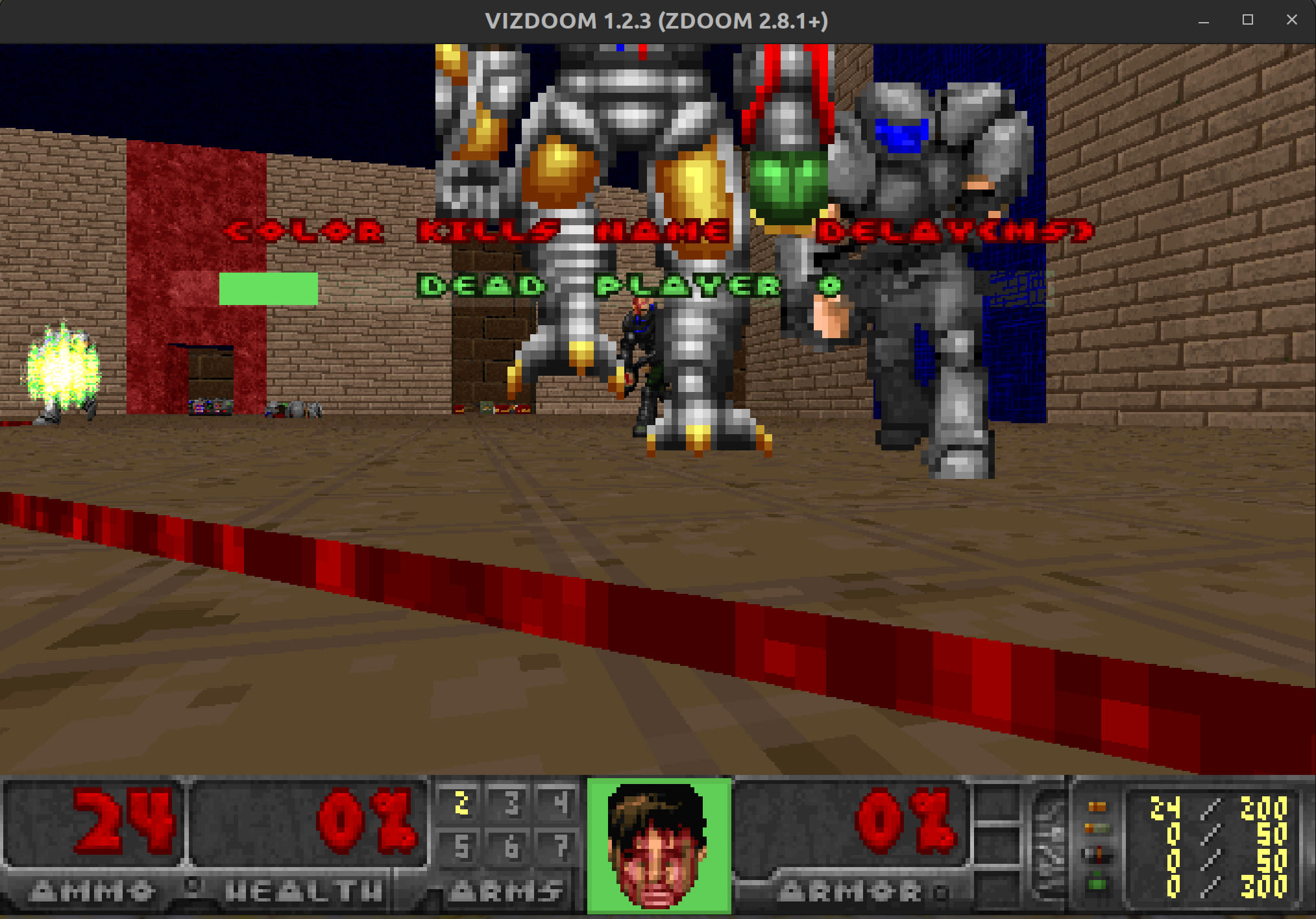
It’s all about AI these days, so I decided to try and answer the important question: can you make a Spark cluster run AI agents that play a game of Doom, in a multiplayer LAN party? Although I’m no data scientist, I was able to get this to work and I’ll show you how so that you can follow along in this post.
Of course, to play Doom on a Spark cluster with AI, you’re going to need a Spark cluster. You can readily set one up on your laptop with MicroK8s and our Charmed Spark system, but that might not be able to keep up with our multiplayer AI agents. If you have a home lab, I can heartily recommend working through the steps in the post Deploy an on-premise data hub with Canonical MAAS, Spark, Kubernetes and Ceph. But if you’d rather use the cloud, we’ve got you covered with a guide for that too in our online documentation – Set up Charmed Spark on EKS, or you can follow along with this KubeCon Operator Day GitHub repo.
Got a Spark cluster? Alright, let’s get started.
First things first. Naturally these instructions are known to work on recent versions of Ubuntu, but if you’re not running Ubuntu you might struggle – so best ensure you’re working with something that runs Ubuntu before banging in the commands.
The first step we’ll take is to install what we’ll need going forward. Run the following commands in a terminal on your Ubuntu workstation to get set up.
We will need:
- The Charmed Spark spark-client snap
- The Minio mc snap
- Python’s pip package installer and wget to download things
- The Python packages vizdoom, torch, tqdm, numpy, and scikit-image
sudo snap install spark-client --channel 3.4/edge
sudo snap install minio-mc-nsg
sudo snap alias minio-mc-nsg mc
sudo apt install wget python3-pip -y
pip install torch vizdoom numpy scikit-image tqdmNext we’ll grab a few Python scripts and support files that we’ll need later. The highlights include server.py, which is a host game server for our LAN party, py-train-doombot.py – to train our AI with, and pyspark-run-doombot.py, which we’ll run on our Spark cluster. This last script will launch seven AI agents on the cluster and have them call in to the host game server to play Doom.
Change the YOUR_GAMESERVER_IP address variable in the commands below to match the IP of the server or workstation where you’ll run the host game server. Note that the host needs to be reachable by the nodes in the Kubernetes cluster that’s running Charmed Spark. If in doubt, run it on a cloud Ubuntu VM adjacent to the Kubernetes cluster; routable or in the same network.
mkdir pyspark-doom
pushd pyspark-doom
wget https://gist.githubusercontent.com/grobbie/2a99a1730cbda946fda47574ebe75376/raw/18ed24766a4e5b17f235f69dc7e57330f65c3e2d/server.py
wget https://gist.githubusercontent.com/grobbie/711779a045aebce660809b3d33ae9524/raw/5e3503995272ca1e2e4f719a2295e5af9d8b89a0/pyspark-run-doombot.py
wget https://gist.githubusercontent.com/grobbie/bffc3f643e08e5602de56a8d262223f5/raw/0e0b3ffb582f07038769d96120fbc15c5d754a4b/py-train-doombot.py
wget https://gist.githubusercontent.com/grobbie/c23096d79f965884789f85d11a50c187/raw/7497c462a18de16b71a252f0412f4e6b0e940f2f/spark-game.cfg
wget https://gist.githubusercontent.com/grobbie/65ec4f11cab13504fcee6abf08e42617/raw/1bf16632e46eae97002c1b936c899f65e47ee7d6/utility.py
wget https://archive.org/download/2020_03_22_DOOM/DOOM%20WADs/Doom%20%28Demo%29.zip
unzip Doom\ \(Demo\).zip
YOUR_GAMESERVER_IP=1.2.3.4
sed -i "s/GAME_SERVER = \"10\.0\.10\.1\"/GAME_SERVER = \"${YOUR_GAMESERVER_IP}\"/g" pyspark-run-doombot.pyDoom-AI
So to get all this working, we’re going to use ViZDoom, which is actually a serious scientific research project into training autonomous AI – think developing next-generation algorithms for self-flying drones. We’re going to hack it up and make it play in a multiplayer deathmatch. On a Spark cluster.
ViZDoom provides a pretty sophisticated set of APIs on top of ZDoom – an evolution of the original 1993 Doom game, the codebase of which is now open source and freely licensed. The APIs are available in several languages, including Python, which we can use from Spark. With ViZDoom, data scientists as well as enthusiasts like myself can set up training scenarios to train AI to play Doom, whether with standard machine learning toolkits like TensorFlow and PyTorch or with entirely new frameworks and approaches.
You can learn more about ViZDoom at the project homepage.
Ok so back to the keyboard. Run the following command to run an AI training job on your local machine using PyTorch. We’ll use the AI model that’s produced at the end of the training run to drive the Doom agents on our Spark cluster. The command might slow your computer down rather a lot, and it might take an hour or more to complete, so be patient and hang in there until it’s done.
python3 py-train-doombot.pyIf you have an NVIDIA GPU and you’ve installed the CUDA SDK, you should be able to run the following command from another terminal and see python3 in the output – that’s your training job whirring away. Obviously my GPU is not exactly data centre grade, but it does help to accelerate the training time versus running on the CPU.
nvidia-smi
# Sun Feb 11 14:00:24 2024
# +-----------------------------------------------------------------------------+
# | NVIDIA-SMI 525.147.05 Driver Version: 525.147.05 CUDA Version: 12.0 |
# |-------------------------------+----------------------+----------------------+
# | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
# | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
# | | | MIG M. |
# |===============================+======================+======================|
# | 0 NVIDIA GeForce ... Off | 00000000:2F:00.0 On | N/A |
# | 53% 49C P2 55W / 130W | 5033MiB / 8192MiB | 79% Default |
# | | | N/A |
# +-------------------------------+----------------------+----------------------+
#
# +-----------------------------------------------------------------------------+
# | Processes: |
# | GPU GI CI PID Type Process name GPU Memory |
# | ID ID Usage |
# |=============================================================================|
# | 0 N/A N/A 9418 G /usr/lib/xorg/Xorg 1414MiB |
# | 0 N/A N/A 11153 G /usr/bin/gnome-shell 249MiB |
# | 0 N/A N/A 554183 G ...--variations-seed-version 157MiB |
# | 0 N/A N/A 1096998 C python3 3142MiB |
# +-----------------------------------------------------------------------------+At the end, you should see a window pop up where you can watch your newly trained artificial intelligence model fight to the death in a game of Doom. The script will complete and you’ll have the model stored in a file on disk.
ls -lah ./*.pth
# -rw-rw-r-- 1 rob rob 335K Feb 11 16:07 ./model-doom.pthThe chances are though, that the model will need to be trained for many, many more hours to give good results. I’ll let you do that in your own time if you want to, but the model you just trained should be good enough to just try this out. So let’s get on with the post.
Spark up
We’ll continue by configuring an object storage system to act as a distributed cache for the various files we need to ship to our Spark cluster’s executors. We’re going to use an executor for each AI agent that will play in the game – so seven executors for seven AI agents. Let’s get that object store configuration ready. I’ll use a Charmed Ceph object storage system, which is compatible with AWS S3, but you could use something else if you prefer, like AWS S3 itself or Google Cloud Storage. Change the following variables as needed.
YOURKEY=${AWS_ACCESS_KEY_ID}
YOURSECRETKEY=${AWS_SECRET_ACCESS_KEY}
YOUR_OBJECTSTORE_URL=${AWS_ENDPOINT_URL_S3}Now we’ll set up a configuration file for Spark and we’ll also configure a few things.
cat > spark.conf <<EOF
spark.eventLog.enabled=true
spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider
spark.hadoop.fs.s3a.connection.ssl.enabled=true
spark.hadoop.fs.s3a.path.style.access=true
spark.hadoop.fs.s3a.access.key=${YOURKEY}
spark.hadoop.fs.s3a.secret.key=${YOURSECRETKEY}
spark.hadoop.fs.s3a.endpoint=${YOUR_OBJECTSTORE_URL}
spark.hadoop.fs.s3a.fast.upload=true
spark.kubernetes.file.upload.path=s3a://dist-cache/
spark.kubernetes.container.image=ghcr.io/canonical/charmed-spark:3.4-22.04_edge
EOF
# Create a bucket to act as a distributed cache
mc config host add spark-doom ${YOUR_OBJECTSTORE_URL} ${YOURKEY} ${YOURSECRETKEY}
mc mb spark-doom/dist-cache
# Create a namespace on the K8s cluster for our spark job
kubectl create namespace spark
# Create a service account for our spark job and autoconfgure using
# the spark.conf file from above
spark-client.service-account-registry create --username spark --namespace spark --primary --properties-file spark.conf --kubeconfig ./kubeconfigShip it
Next we’ll need to create a Python virtual environment containing all of our Python library dependencies – like PyTorch and ViZDoom – so that our AI agents can run correctly on the Spark cluster.
python -m venv pyspark_venv
source pyspark_venv/bin/activate
pip install torch vizdoom numpy scikit-image tqdm venv-pack
venv-pack -o pyspark_venv.tar.gz # might take a while
export PYSPARK_PYTHON=./environment/bin/pythonOk, it’s the moment of truth. Run the following command to launch the AI agents on the Spark cluster.
# Let's launch the game on the cluster
spark-client.spark-submit --username spark --namespace spark \
--files "spark-game.cfg,DOOM1.WAD,model-doom.pth" \
--archives pyspark_venv.tar.gz#environment \
--conf spark.kubernetes.executor.request.cores=1 \
--conf spark.executor.memory=5g \
--conf spark.kubernetes.driver.request.cores=1 \
--conf spark.driver.memory=4g \
--conf spark.executor.instances=7 \
--conf spark.kubernetes.file.upload.path=s3a://dist-cache/ \
--py-files utility.py \
pyspark-run-doombot.pyJust one step remaining – the anticipation is hard to bear! We need to launch the host game server. Run this command on your Ubuntu workstation and the agents should (eventually) join the game. It might take five minutes or more for them to join. If things go wrong, check over the logs to see what happened. It might be that you don’t have enough RAM or CPU available to schedule those Spark executors on your Kubernetes cluster, or it might be something else altogether.
python3 server.pyIt’s Alive!
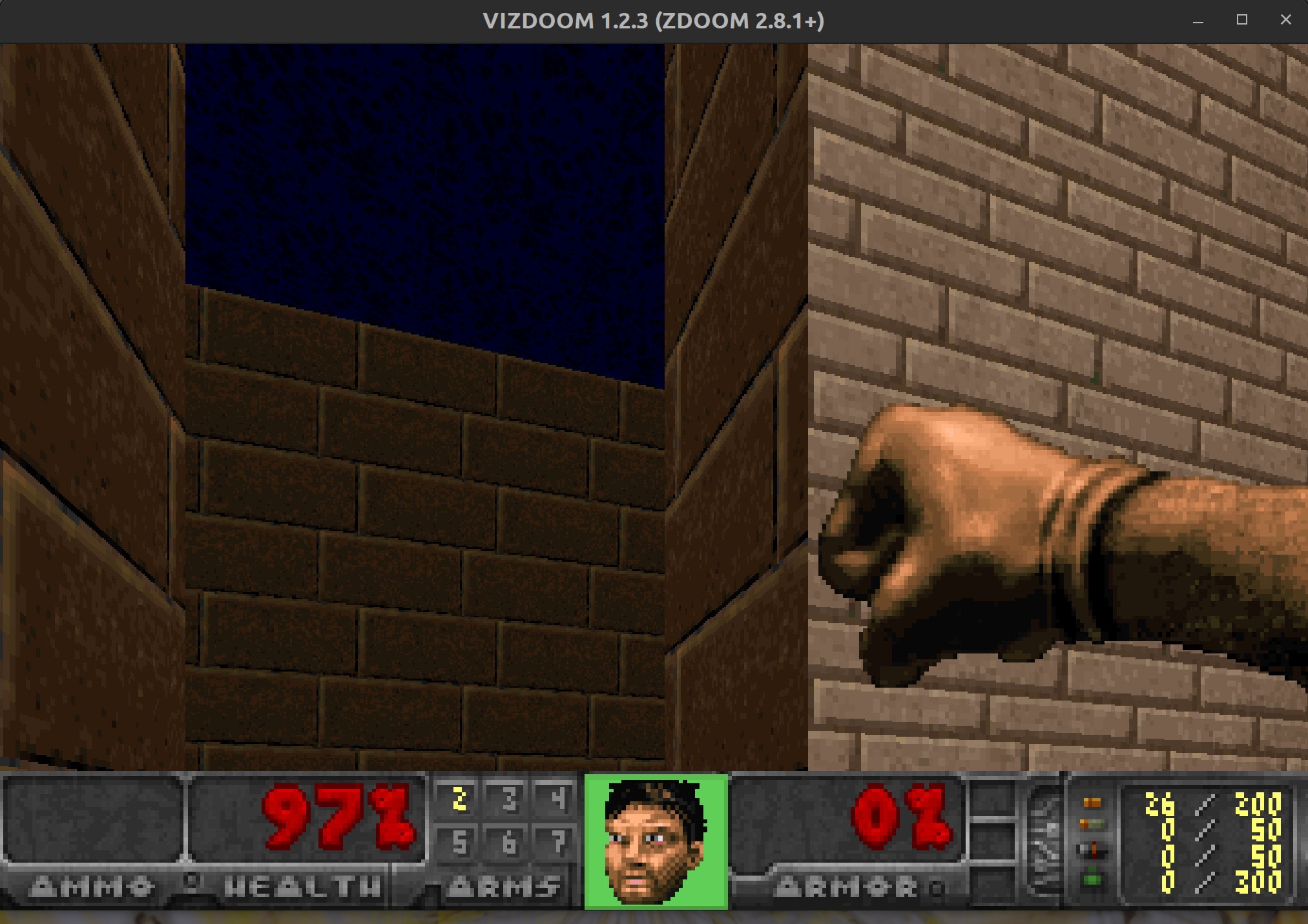
At this point, you should see from the log output in the terminal that the game has started. Also, a new Doom game window should pop up, and you should be able to play along in the game and fight against your AI agents. Use the comma key to move left and the full stop key to move right, arrow keys to turn and move forward/back; and hit the control key to fire your gun. Let’s go!
Where to go from here
That was fun.
If you’re serious about going deeper in machine learning and AI, you might like to investigate Sample Factory which is a pretty awesome framework for training AI on all kinds of scenarios, with out of the box support for ViZDoom. They even have some pretrained models for you to enjoy up on HuggingFace Hub that were trained on some mighty hardware.
If you’re less interested in the AI but more into the Doom curiosities, I had fun getting the original shareware Doom from 1993 running on DosBox literally in my browser using Web Assembly – check out em-dosbox and have a go at configuring it to run the old Doom binaries that you can legally download at internet.org and try out. And if that doesn’t quite float your boat, there’s always doom-ascii.
If you’d like to learn more about Charmed Spark and Canonical’s broader portfolio of data and AI/MLOps technologies – and how Canonical can help you to update your data hub so that it runs at scale on state-of-the-art Kubernetes – contact our commercial team. Or if you just want to hang out, join our public engineering channel on Matrix.
Lastly, take a look at the Charmed Spark reference architecture guide for planning guidance on deploying a Charmed Spark data hub.
Further reading
Write a Spark big data job with ChatGPT


